python爬虫爬取网页
0
-
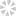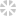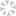
python爬虫爬取某图书网页实例讲解
目录导入相应的库设置循环遍历遍历URL保存图片和文档下面是通过requests库来对AJAX页面进行爬取的案例,与正常页面不同,这里我们获取url的方式也会不同,这里我们通过爬取一个简单的ajax小说页面来为大家讲解。(注[详细]
2024-08-30 09:16 分类:开发 Is it possible to run Weblogic with 8gb heap size in a 64bit java/linux environment
Setup: 64bit Linux 64bit SUN Jvm 1.6.0_20 Weblogic 10.3 Is it possible to run Weblogic 10.3 in this setup with a maximum heap size of 8gb? We have recived answers from oracle support that states t[详细]
2022-12-28 19:14 分类:问答








 加载中,请稍侯......
加载中,请稍侯......