Python爬虫
python爬虫控制aiohttp并发数量方式
目录前言解决上述问题目前想到两个方法实验结果总结前言 在使用aiohttp并发访问多个页面时效率,明显比串行requests快很多,[详细]
2024-08-10 09:42 分类:开发盘点总结Python爬虫常用库(附官方文档)
目录一、Requests - 构建HTTP请求示例代码:获取网页内容二、Beautiful Soup - 解析html和XML示例代码:提取网页标题三、Scrapy - 构建爬虫示例代码:创建爬虫项目四、Selenium - 自动化浏览器操作示例代码:模拟登录[详细]
2023-11-19 09:28 分类:开发使用Python实现简单的爬虫框架
目录一、请求网页二、解析 html三、构建爬虫框架爬虫是一种自动获取网页内容的程序,它可以帮助我们从网络上快速收集大量信息。在本文中,我们将学习如何使用 python 编写一个简单的爬虫框架。[详细]
2023-05-08 09:28 分类:开发Python爬虫中的并发编程详解
目录并发编程在爬虫中的应用什么是并发编程并发编程在爬虫中的应用单线程版本多线程python版本异步I/O版本并发编程在爬虫中的应用[详细]
2023-05-05 09:57 分类:开发-
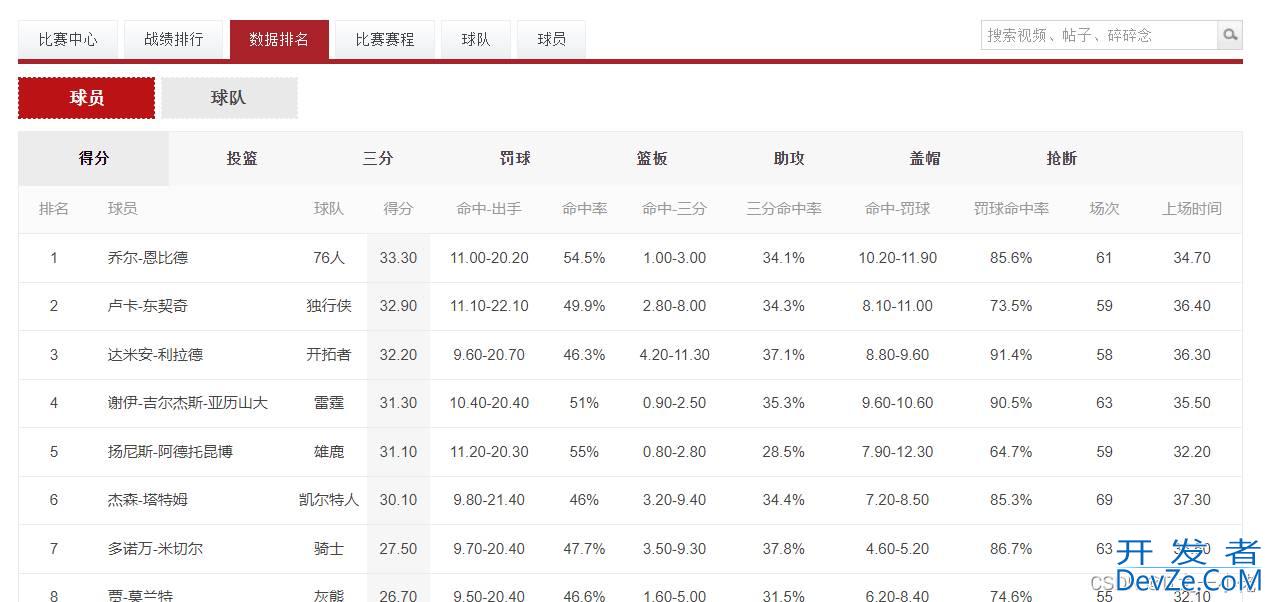
关于python简单的爬虫操作(requests和etree)
虎扑体育-NBA球员得分数据排行 第1页 示例代码: import requests from lXML import etree[详细]
2023-04-19 09:18 分类:开发 Python网络编程实战之爬虫技术入门与实践
目录一、简介二、爬虫技术基础概念三、请求与响应四、html解析与数据提取五、实战:爬取简书网站首页文章信息六、存储数据七、测试与优化1.遇到反爬虫策略时,可以使用User-Agent伪装成浏览器。2.使用time.sleep()函[详细]
2023-04-04 09:44 分类:开发Python爬虫之使用BeautifulSoup和Requests抓取网页数据
目录一、简介二、网络爬虫的基本概念三、Beautiful Soup 和 Requests 库简介四、选择一个目标网站五、使用 Requests 获取网页内容六、使用 Beautiful Soup 解析网页内容七、提取所需数据并保存八、总结及拓展一、简介[详细]
2023-04-04 09:19 分类:开发Python使用爬虫爬取贵阳房价的方法详解
目录1 序言1.1 生存压力带来的哲思1.2 买房&房奴2 爬虫 2.1 基本概念2.2 爬虫的基本流程 3 爬取贵阳房价并写入表格3.1 结果展示3.2 代码实现(python) 总结1 序言[详细]
2022-12-10 12:32 分类:开发一篇文章带你了解Python之Selenium自动化爬虫
目录python之Selenium自动化爬虫0.介绍1.安装2.下载浏览器驱动3.实例4.开启无头模式5.保存页面截图6.模拟输入和点击a.根据文本值查找节点b.获取当前节点的文本c.打印当前网页的一些信息d.关闭浏览器e.模拟鼠标滚动7.[详细]
2022-12-09 12:46 分类:开发







 加载中,请稍侯......
加载中,请稍侯......