目录
- 准备工作
- 安装必要的库
- 读取PDF文件
- 代码读取示例
- 加密PDF文件
- 使用PyPDF2加密PDF
- 使用Spire.PDF for python加密PDF
- 使用Python设置PDF的安全权限
- 注意事项
- 使用Python解密PDF
- 高阶用法处理
- 1. 错误处理
- 2. 批量处理
- 3. 加密选项的深入理解
- 4. 性能优化
- 5. 安全性考虑
- 6. 学习和探索
- 总结
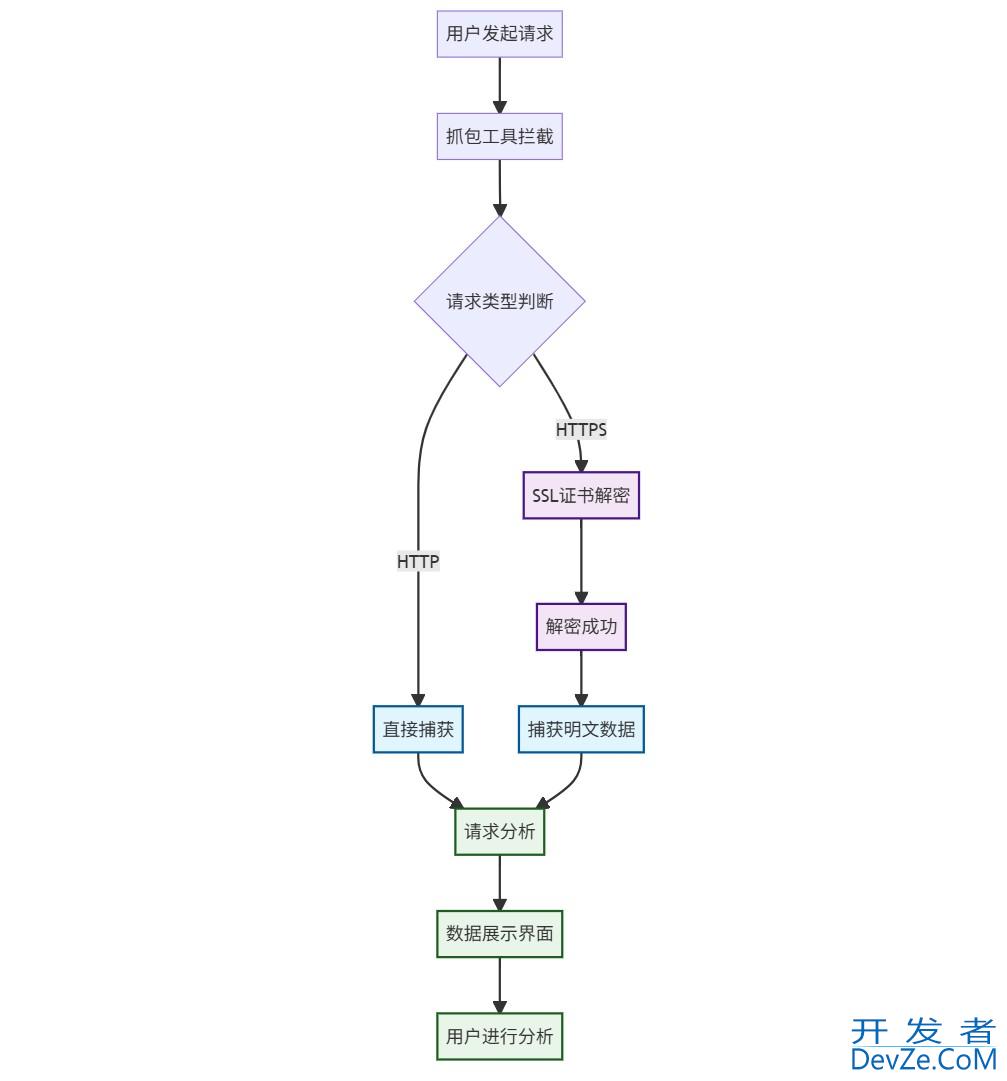
准备工作
在开始之前,确保你的Python环境已经安装好,并安装了处理PDF文件所需的库。这里我们将使用两个主要的库:PyPDF2用于读取PDF内容,PyPDF2和Spire.PDF for Python用于加密PDF文件。
安装必要的库
安装pdfplumber
使用pip安装pdfplumber,这是读取PDF文件内容的一个常用库。
pip install pdfplumber
安装PyPDF2
PyPDF2是另一个用于处理PDF文件的库,支持读取、写入和加密等操作。
pip install PyPDF2
安装Spire.PDF for Python
Spire.PDF for Python是一个功能强大的库,支持多种PDF操作,包括创建、读取、修改和加密。不过,需要注意的是,Spire.PDF for Python并非开源库,通常需要从其官方网站或授权渠道获取。
# 注意:这里只是示例,实际安装可能需要从官网下载或使用其他方式 pip install Spire.Pdf
如果无法从pip直接安装,可以访问Spire.PDF for Python的官方网站下载并安装。
读取PDF文件
在Python中,使用pdfplumber库都可以很方便地读取PDF文件的内容。以下是一个使用PyPDF2读取PDF文件内容的基本示例。
我们先查看下PDF文件

代码读取示例
def read_pdf(path)php:
#pip install pdfplumber
import pdfplumber
with pdfplumber.open(path) as pdf:
# for i in range(len(pdf.pages)):
# page = pdf.pages[i]
# print(page.extract_text())
for page in pdf.pages:
print(page.extract_text())
if __name__ == "__main__":
read_pdf('基于Python编写的FTP程序.pdf')

上述代码通过extract_text函数读取了指定路径的PDF文件内容,并打印出来。extract_text函数会自动处理PDF中的文本内容,包括文本布局、字体和编码等。
加密PDF文件
加密PDF文件是为了保护文件内容不被未授权访问。在Python中,可以使编程用PyPDF2和Spire.PDF for Python库来实现PDF文件的加密。
使用PyPDF2加密PDF
PyPDF2是一个强大的库,用于处理PDF文件的各种操作,包括加密。以下是一个使用PyPDF2加密PDF文件的基本示例。
示例代码
import PyPDF2
def encrypt_pdf_with_pypdf2(input_pdf, output_pdf, password):
# 创建PdfFileReader和PdfFileWriter对象
pdf_reader = PyPDF2.PdfReader(input_pdf)
pdf_writer = PyPDF2.PdfWriter()
# 逐页添加内容到写入器
for page_num in pdf_reader.pages:
pdf_writer.add_page(page_num)
# 加密PDF文件
pdf_writer.encrypt(password)
# 写入加密后的PDF文件
with open(output_pdf, 'wb') as output_file:
pdf_writer.write(output_file)
print(f"PDF文件 {input_pdf} 已加密, 并保存为 {output_pdf}")
# 使用示例
encrypt_pdf_with_pypdf2('基于Python编写的FTP程序.pdf', 'encrypted_example.pdf', 'mysecretpassword')
在上述代码中,我们首先读取了一个PDF文件,然后逐页将其内容添加到PdfFileWriter对象中。最后,我们使用encrypt方法设置了一个密码,并将加密后的PDF文件保存到新的文件中。

打开pdf文件,已被加密

使用Spire.PDF for Python加密PDF
虽然PyPDF2是一个很好的库,但Spire.PDF for Python提供了更多高级功能,包括更强大的加密选项。以下是一个使用Spire.PDF for Python加密PDF文件的示例。
要加密PDF,你需要设置用户密码(文档打开密码),该密码将用于打开和查看文件。
什么是用户密码(文档打开密码)?
用户必须输入该密码才能打开和查看PDF文档。
它限制对PDF内容的访问,确保只有授权个人才能访问该文件。用户密码不提供除打开PDF之外的任何其他权限或限制。除了设置用户或打开密码外,你还需要设置用于保护PDF内容的加密级别或算法。Spire.PDF for Python支持以下加密级别或算法:40-bit RC4
128-bit RC4128-bit AES256-bit AES使用Python加密PDF文件的主要步骤如下:创建PdfDocument实例,并使用PdfDocument.LoadFromFile()方法加载PDF文件。
创建一个PdfSecurityPolicy,并设置打开文档所需的用户密码。通过PdfSecurityPolicy类中的EncryptionAlgorithm属性设置用于保护PDF的加密算法。使用PdfDocument.Encrypt(securityPolicy:PdfSecurityPolicy)方法应用安全策略以加密PDF文档。将加密的PDF文档保存为新文件。示例代码
首先,请确保你已经正确安装了Spire.PDF for Python库。由于这个库不是通过pip直接安装的,你可能需要从其官方网站下载相应的Python包,并按照提供的说明进行安装。
from spire.pdf import *
# 创建document对象
doc = PdfDocument()
# 加载需要加密的现有PDF文件
doc.LoadFromFile("基于Python编写的FTP程序.pdf")
# 创建一个安全策略,并设置打开文档所需的用户密码
securityPolicy = PdfPasswordSecurityPolicy("userpassword", str())
# 指定用于保护PDF的加密算法
securityPolicy.EncryptionAlgorithm = PdfEncryptionAlgorithm.AES_256
# 应用安全策略以加密PDF文档
doc.Encrypt(securityPolicy)
# 保存加密后的PDF文档
doc.SaveToFile("加密.pdf")
print("PDF文件 基于Python编写的FTP程序.pdf 已加密, 并保存为 加密.pdf ")
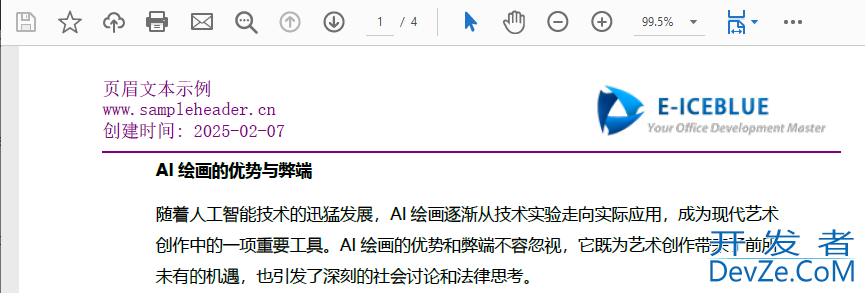
打开加密文件,已被加密

在上述代码中,我们首先使用doc.LoadFromFile方法加载了一个PDF文件。然后,我们创建了一个securityPolicy加密策略,并设置了用户密码、所有者密码、权限和加密级别。这里我们选择了AES 256位加密,并允许打印、修改内容和复制内容。最后,我们通过调用doc.Encrypt方法应用加密,并使用doc.SaveToFile方法保存加密后的PDF文件。
使用Python设置PDF的安全权限
要为PDF文档设置安全权限,除了用户密码外,你还需要设置所有者密码(权限密码)。
什么是所有者密码(权限密码)?
用于控制可在PDF文档上执行的权限和操作。
允许文档所有者限制某些操作,例如打印、复制、修改或从PDF中提取内容。所有者密码通常比用户密码更强大,因为它赋予所有者对PDF安全设置的完全控制。使用Python设置PDF安全权限的主要步骤如下:
- 创建PdfDocument实例,并使用PdfDocument.LoadFromFile()方法加载一个PDF文件。
- 创建一个PdfSecurityPolicy,并设置打开文档所需的用户密码和用于限制权限的所有者密码。
- 通过PdfSecurityPolicy类中的EncryptionAlgorithm属性设置用于保护PDF的加密算法。
- 禁止所有权限,然后通过PdfSecurityPolicy类中的DocumentPrivilege属性赋予特定权限。
- 使用PdfDocument.Encrypt(securityPolicy:PdfSecurityPolicy)方法应用安全策略以加密PDF文档。
- 将加密的PDF文档保存为新文件。
以下代码示例展示了如何使用Python设置PDF的安全权限:
from spire.pdf import *
# 创建PdfDocument对象
pdf = PdfDocument()
# 加载需要加密的现有PDF文件
pdf.LoadFromFile("基于Python编写的FTP程序.pdf")
# 创建一个安全策略,并设置打开文档所需的用户密码和用于限制权限的所有者密码
securityPolicy = PdfPasswordSecurityPolicy("userpassword", "ownerpassword")
# 设置加密算法
securityPolicy.EncryptionAlgorithm = PdfEncryptionAlgorithm.AES_256
# 禁止所有权限
securityPolicy.DocumentPrivilege = PdfDocumentPrivilege.ForbidAll()
# 仅允许打印文档
securityPolicy.DocumentPrivilege.Allowprint = True
# 加密所有文档内容,除了元数据(可选,用于允许搜索引擎访问文档的元数据)
# securityPolicy.EncryptMetadata = False
# 应用安全策略以加密PDF文档
pdf.Encrypt(securityPolicy)
# 将加密的PDF文档保存为新文件
pdf.SaveToFile("安全权限.pdf")
pdf.Close()
运行生成加密后的文件,打开需要密码userpassword

编辑需需要密码ownerpassword

我们看下有哪些权限

注意事项
- 在使用加密功能时,请确保你了解不同加密级别和权限设置的影响。
- 加密后的PDF文件将需要密码才能打开或进行某些操作,因此请确保你妥善保管密码。
- 如果你在处理大量PDF文件或需要更高级的功能(如数字签名、表单填充等),考虑使用更专业的库,如
Spire.PDF for Python。
使用Python解密PDF
加密的PDF文件可以使用其用户密码或所有者密码打开。打开后,你可以使用PdfDocument.Decrypt()方法对其进行解密。
使用Python解密加密PDF文件的主要步骤如下:
创建PdfDocument实例,并使用PdfDocument.LoadFromFile()方法加载加密的PDF文件。
调用PdfDocument.Decrypt()方法解密PDF文件。将解密后的PDF文件保存为新文件。以下代码示例展示了如何使用Python解密PDF文件:
from spire.pdf import *
# 创建PdfDocument对象
pdf = PdfDocument()
# 使用用户密码或所有者密码打开加密的PDF文档
pdf.LoadFromFile("安全权限.pdf", "userpassword")
# 解密PDF文档
pdf.Decrypt("ownerpassword")
# 将解密后的文档保存为新文件
pdf.SaveToFile("解密后文件.pdf")
pdf.Close()
javascript

解密后的pdf直接能打开。
当然,我们可以继续探讨一些高级话题和最佳实践,特别是在处理PDF文件时。以下是一些额外的考虑点和技巧,可以帮助你更有效地在Python中处理PDF文件。
高阶用法处理
1. 错误处理
在处理文件时,错误处理是非常重要的。无论是读取文件还是写入文件,都可能会遇到各种问题,如文件不存在、权限不足、磁盘空间不足等。因此,在你的代码中添加适当的错误处理逻辑是很重要的。
try:
# 尝试读取或写入PDF文件的代码
# ...
except FileNotFoundError:
print(f"文件 {file_path} 未找到。")
except PermissionError:
print(f"没有权限访问文件 {file_path}。")
except Exception as e:
print(f"处理文件时发生错误:{e}")
2. 批量处理
如果你需要处理多个PDF文件,编写一个能够批量处理这些文件的脚本将非常有用。你可以使用Python的循环结构(如for循环)来遍历文件列表,并对每个文件执行相同的操作。
import os
def process_pdfs(folder_path, output_folder, password):
# 获取文件夹中所有PDF文件的列表
pdf_files = [f for f in os.listdir(folder_path) if f.endswith('.pdf')]
# 遍历文件列表并处理每个文件
for file in pdf_files:
input_path = os.path.join(folder_path, file)
output_path = os.path.join(output_folder, f"encrypted_{file}")
# 这里可以调用加密函数
# encrypt_pdf(input_path, output_path, password)
# 示例:仅打印将要处理的文件路径
print(f"正在处理 {input_path} ...")
# 使用示例
process_pdfs('input_pdfs', 'output_pdfs', 'mysecretpassword')
3. 加密选项的深入理解
当你使用PyPDF2或Spire.PDF for Python等库加密PDF文件时,了解不同的加密选项和权限设置是非常重要的。例如,你可以设置不同的用户密码和所有者密码,以及控制哪些操作(如打印、修改、复制等)被允许。
- 用户密码:用于打开和查看PDF文件。
- 所有者密码:用于修改PDF文件的加密设置,包括更改密码和权限。
- 权限:定义了对PDF文件可以执行哪些操作,如打印、修改内容、复制内容等。
4. 性能优化
如果你需要处理大型PDF文件或大量文件,性能可能会成为一个问题。以下是一些优化性能的方法:
- 使用多线程或多进程:Python的
threading和multiprocessing模块可以帮助你并行处理多个文件,从而加快处理速度。 - 内存管理:确保你的脚本不会消耗过多的内存。在处理大型文件时,考虑使用流式处理或分批处理文件内容。
- 选择高效的库:不同的库在处理PDF文件时的性能可能会有所不同。根据你的具体需求选择最合适的库。
5. 安全性考虑
当你加密PDF文件时,请确保你使用的加密方法和密码足够强大,以防止未经授权的访问。以下是一些安全性考虑点:
- 使用强密码:选择包含大小写字母、数字和特殊字符的复杂密码。
- 定期更改密码:如果你经常处理敏感信息,请定期更改你的加密密码。
- 了解加密算法的局限性:虽然AES等现代加密算法非常强大,但它们也有其局限性。了解你选择的加密算法的优缺点是很重要的。
6. 学习和探索
PDF处理是一个广泛而复杂的领域,有许多不同的库和工具可供选择。除了PyPDF2和Spire.PDF for Py编程客栈thon之外,还有其他一些流行的库,如pdfplumber(用于提取文本和表格)、ReportLab(用于创建PDF文件)等。花时间学习和探索这些库将帮助你更好地处理PDF文件。
希望这些额外的信息和技巧对你有所帮助!如果你有任何其他问题或需要进一步的帮助,请随时提问。
总结
在Python中读取和加密PDF文件是一个相对直接的过程,通过使用PyPDF2或Spire.PDF for Python等库,你FiJnSVT可以轻松地实现这些功能。根据你的具体需求(如加密级别、性能要求、预算等),你可以选择最适合你的库。希望本文对你有所帮助!
以上就是Python中读取和加解密PDF文件的详细教程的详细内容,更多关于Python读取和加解密PDF的资料请关注编程客栈(www.devze.com)其它相关文章!


 加载中,请稍侯......
加载中,请稍侯......
精彩评论