上一篇:PostgreSQL索引失效会发生什么
PostgreSQL逻辑复制解密原理解析:下一篇
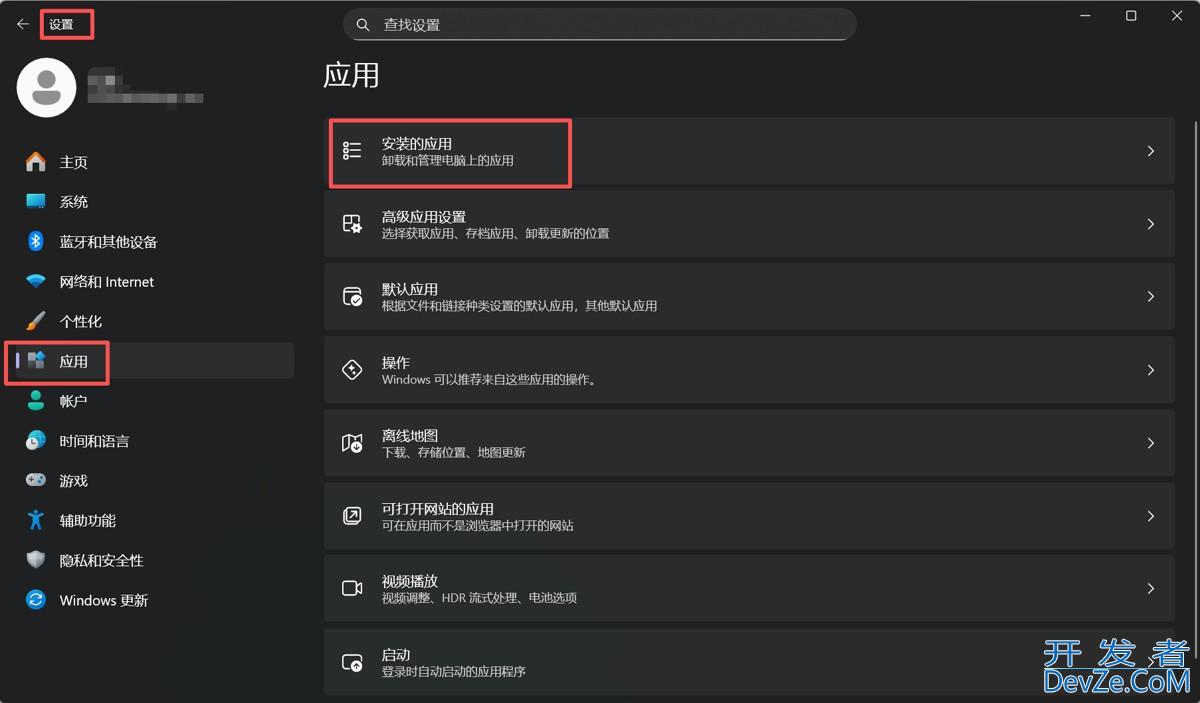
SQL Server彻底卸载的终极指南(不重装系统,超级干净)
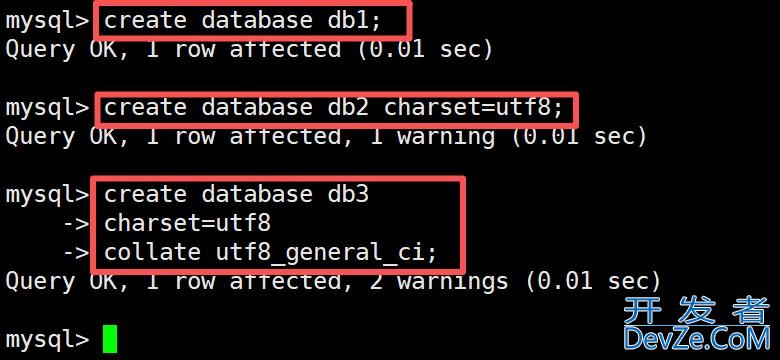
MySql库与表的基础操作大全
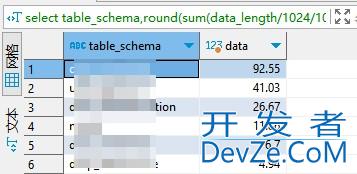
统计mysql和pgsql库和表占用大小方式
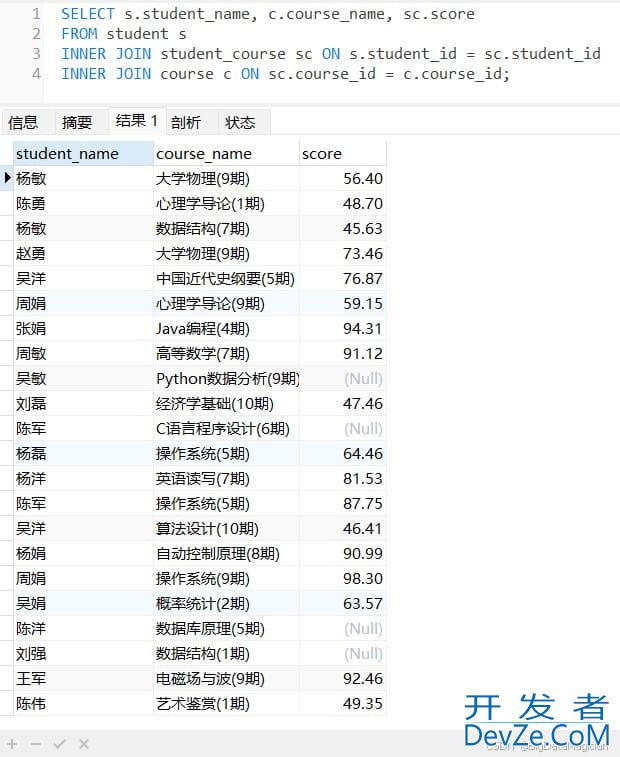
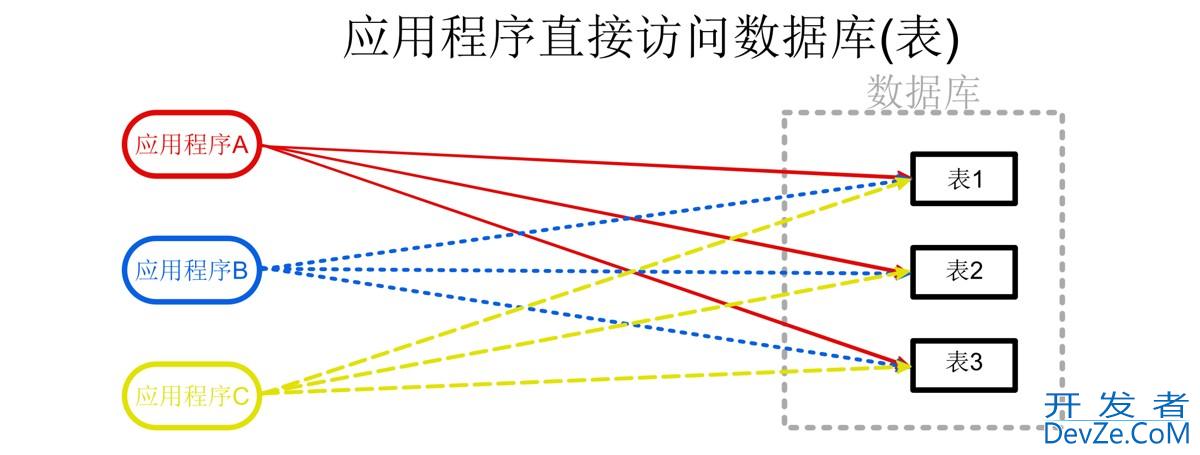
MySQL数据连接查询和子查询操作过程
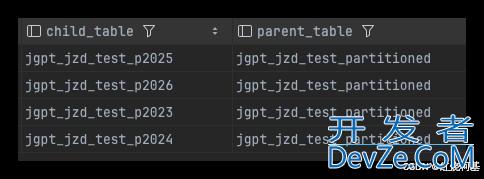
PostgreSQL表分区的三种方式和操作方法
MySQL root密码忘了的超详细重置步骤教程
MySQL存储过程、游标与触发器示例详解
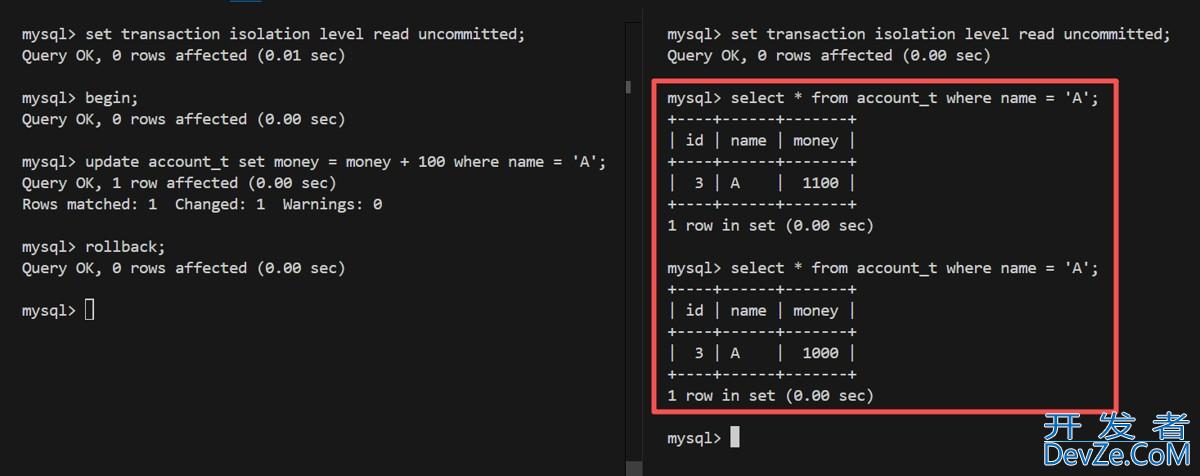
MySQL的事务机制与并发读异常示例详解

 加载中,请稍侯......
加载中,请稍侯......
精彩评论