目录
- 什么是 Redis 热点 Key?
- 发现 Redis 热点 Key 的方法
- 1. Redis Monitor 和 Slowlog
- 2. Key 访问统计
- 3. 使用 Redis 命令行工具 redis-rdb-tools
- 4. 高级工具:aof 解析和插件
- Redis 热点 Key 解决方案
- 1. 数据分片
- 2. 缓存淘汰策略
- 3. 请求合并
- 4. 数据预热
- 5. 限流和降级
- 6. 使用多级缓存
- 7. 避免大的Key和Value
- 8. 定期清理和监控
- 结论
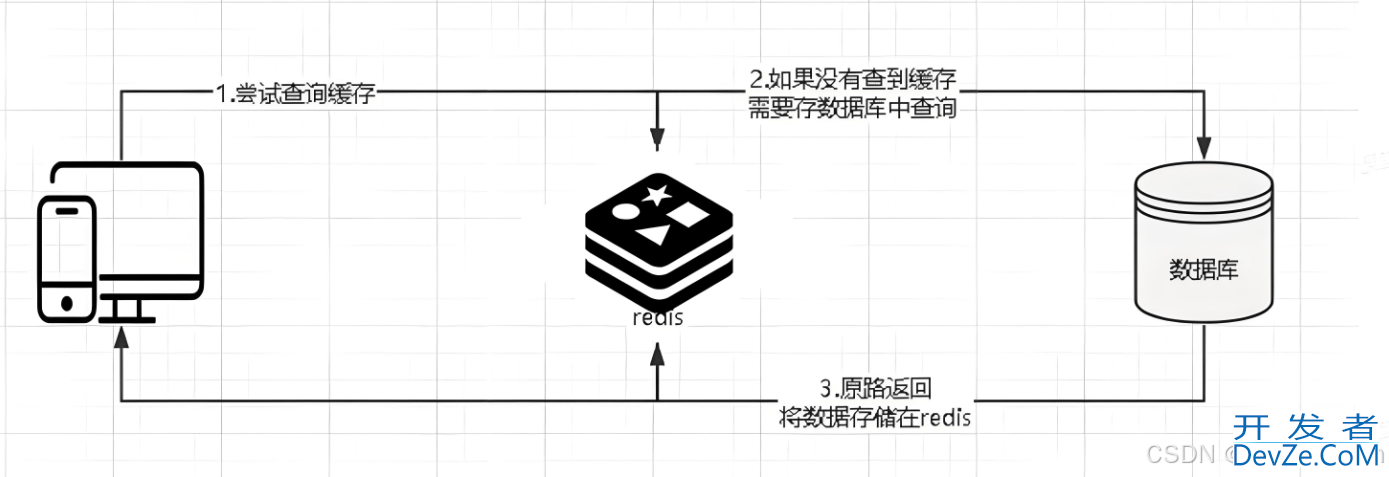
什么是 Redis 热点 Key?
Redis 热点 Key 是指在某一时间段内,被大量的读写操作命中的 Key。这种情况可能会导致以下问题:
- 性能瓶颈:集中在某一节点的请求可能会超过该节点的处理能力,导致延迟增加。
- 数据一致性问题:多个客户端对同一个 Key 执行大量写操作,可能导致数据库不一致。
- 缓存击穿:如果热点 Key 突然失效,大量缓存未命中的请求可能会击穿缓存,造成后端数据库压力剧增。
发现 Redis 热点 Key 的方法
1. Redis Monitor 和 Slowlog
Redis 自带的 MONITOR 和 SLOWLOG 命令可以帮助我们监控和诊断性能问题。
MONITOR
MONITOR 命令会实时打印出服务器接收到的每条命令。通过以下命令开启 MONITOR 模式:
redis-cli MONITOR
在大量请求的情况下,使用 grep 或其他文本处理工具可以帮助我们过滤出热点 Key。然而,请谨慎使用 MONITOR,因为它会对性能造成显著影响,不推荐在生产环境中长期使用。
SLOWLOG
Redis SLOWLOG 可以记录执行时间超过指定毫秒数的命令。通过以下命令开启 SLOWLOG :
config set slowlog-log-slower-than 1000 # 设置记录超过 1000 微秒(1 毫秒)的操作 config set slowlog-max-len 1024 # 设置 SLOWLOG 最大长度 slowlog get # 获取 slowlog 记录
2. Key 访问统计
除了直接使用 Redis 自带命令,还可以借助统计脚本或第三方工具获取 Key 的访问频率。例如,通过 redis-cli 和 Bash 脚本,我们可以统计一段时间内各 Key 的访问量。
#!/bin/bash END=$(redis-cli dbsize); for i in $(seq 0 $END); do KEY=$(redis-cli randomkey); redis-cli object freq $KEY; done
3. 使用 Redis 命令行工具 redis-rdb-tools
redis-rdb-tools 是一个 Redis 数据分析工具,可以帮助我们分析 RDB 文件,找出大 Key 及其频率。
pip install rdbtools rdb --command memory ./dump.rdb --bytes > memory.csv
生成的 ythonp;memory.csv 包含了各 Key 的内存占用情况,结合 MEMORY USAGE 命令,我们也可以了解每个 Key 的大小。
4. 高级工具:aof 解析和插件
通过解析 Redis 的 AOF 文件或使用 Redis 插件,可以更为详细地分析 Key 访问模式。例如,redis-hotkey 插件可以帮助识别 Redis 的热点 Key。
# 安装 redis-hotkey 插件 git clone https://github.com/carlos1f/redis-hotkey.git cd redis-hotkey make && make install
Redis 热点 Key 解决方案
1. 数据分片
将数据分布到多个 Redis 实例上,可以有效减少单点压力。常见的数据分片策略有:
- 基于 Key 的分片:使用一致性哈希算法将 Key 分配到不同的节点。
- 应用层分片:在应用层实现分片逻辑,按业务规则将请求分发到对应的实例。
以下是一个基于 Twemproxy 的分片示例:
server1:
ip: 127.0.0.1
port: 6379
weight: 1
server2:
ip: 127.0.0.1
port: 6380
weight: 1
2. 缓存淘汰策略
合适的缓存淘汰策略可以帮助防止缓存击穿问题。常见的策略有:
- LRU(Least Recently Used):最久未使用的 Key 优先被淘汰。
- LFU(Least Frequently Used):使用次数最少的 Key 优先被淘汰。
通过以下命令设置 Redis 的缓存淘汰策略:
config set maxmemory-policy allkeys-lru
3. 请求合并
请求合并策略可以有效减少对同一个 Key 的请求数量。例如,通过 BloomFilter 或 Redis Bitmaps 实现一个请求合并器,将频繁请求合并成一个。
以下是一个简单的请求合并示例:
# 请求合并逻辑
import redis
impowww.devze.comrt time
cache = redis.StrictRedis()
def get_data(key):
if cache.exists(key):
return cache.get(key)
# 请求合并操作
lock_key = f"{key}_lock"
if cache.setnx(lock_key, 1):
cache.expire(lock_key, 5)
# 从数据库读取数据
data = fetchwww.devze.com_data_from_db(key)
cache.set(key, data, ex=60) # 缓存有效时间 60s
cache.delete(lock_key)
return data
else:
time.sleep(0.1) # 等待其他请求获取数据
return cache.get(key)
4. 数据预热
数据预热即在高并发访问之前,将热点数据提前加载进缓存。例如,在每日业务高峰期开始前,提前向缓存加载热点 Key。
5. 限流和降级
当发现热点 Key 后,可以对该 Key 进行限流和降级操作,以保护后台服务。在 Nginx 等代理服务器中可以通过限流模块来限制访问频率。
http {
limit_req_zone $binary_remote_addr zone=req_one:10m rate=1r/s;
server {
...
location / {
limit_req zone=req_one burst=5 nodelay;
}
...
}
}
6. 使用多级缓存
多级缓存可以减少对 Redis 的直接访问。例如,先将数据缓存到本地内存,再通过 Redis 缓存后再访问数据库。
# 多级缓存示例
import time
local_cache = {}
cache = redis.StrictRedis()
def get_data(key):
if key in local_cache:
return local_cache[key]
if cache.exists(key):
data = cache.get(key)
local_cache[key] = data
return data
# 从数据库读取数据
data = fetch_data_from_db(key)
cache.set(key, data, ex=60) # 缓存有效时间 60s
local_cache[key] = data
return data
7. 避免大的Key和Value
尽量避免使用大Key和大Value,因为大的数据在网络传输以及内存分配上都会耗费更多资源。可以将大Key或大Value进行拆分:
- 使用
hash结构将一个大对象进行拆分存储。 - 利用
list或set结构存储大量小对象。
8. 定期清理和监控
通过定期清理无用数据和监控系统,可以及时发现和处理潜在的热点 Key 问题。可以基于 SCAN 命令实现定期数据清理。
# 定期数据清理
import redis
cache = redis.StrictRedis()
def clean_expired_keys():
cursor = '0'
while cursor != 0:
cursor, keys = cache.scan(cursor)
for key in keys:
if cache.ttl(key) == -1:
cache.delephpte(key)
结论
在高并发场景下,Redis 热点 Key 问题会对系统性能与稳定性产生严重影响。本文介绍了多种监控热点 Key 的方法以及针对性解决方案。在实际生产环境中,需要根据具体业务场景选择和组合以上策略,以最优方式解决热点 Key 的问题。
以上就是详解如何发现并解决Redis热点Key问题的详细内容,更多关于Redis热点Key的资料请关注编程客栈(www.devze.comhttp://www.devze.com)其它相关文章!


 加载中,请稍侯......
加载中,请稍侯......
精彩评论